Tiered Distribution
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Version 1.0.1
GotDotNet community for collaboration on this pattern
Complete List of patterns & practices
Context
You are designing the physical infrastructure on which your complex distributed enterprise application will be hosted. You have decided to distribute your application over multiple servers rather than over multiple processors on a multiprocessor computer.
After you have made the decision to distribute your application over multiple computers, you need to consider the consequences from the following three perspectives:
· System architecture. This perspective is fundamentally about servers. Key aspects of this perspective include the number of servers, the role each server plays in the solution, the relationship between servers, and how the multiple servers collaborate together to meet system-level operational requirements.
· Application architecture. This perspective is fundamentally concerned with components. Key aspects of this perspective include packaging components into deployment units, mapping deployment units to operating system processes, and mapping these processes to servers.
· Application administration. This perspective is fundamentally concerned with executable modules, such as DLLs and executable files. Key aspects of this perspective include packaging components into executable modules, delivering and installing the executable modules onto the correct servers, and then configuring them.
This pattern addresses the system architecture perspective. Specifically, it addresses the role each server plays in a solution.
Problem
How should you structure your servers and distribute functionality across them to efficiently meet the operational requirements of the solution?
Forces
The following forces act on a system within this context and must be reconciled as you consider a solution to the problem:
· Components of your application each consume different amounts of resources, such as memory, processor capacity, file handles, IO sockets, disk space, and so on.
· Servers must be configured to provide an efficient environment for solution components.
· A single-server configuration is not likely to meet the requirements of all the components deployed within a complex enterprise application.
· Different servers have different scalability profiles that are determined by the type of components they host. For example, the size of a database may increase at a different rate than the number of users of the solution.
· Different servers have different security requirements that are determined by the type of components they host. For example, components that present information to the user often have different security requirements than components that implement business logic.
· The techniques for meeting availability, reliability and fault-tolerance requirements vary by type of component. For example, the solution's database may be hosted on a single server that is configured for maximum fault-tolerance and high availability, while the Web components may achieve high availability and fault-tolerance through arranging a group of Web servers into a server farm.
· Performance, political, or legal considerations may dictate the geographic locations of specific servers and the components they host. For example, databases containing sensitive corporate information may be hosted at secure corporate data centers, but the application servers that contain the business logic may reside at a third-party hosting facility.
· Every computer boundary that a component invocation crosses adversely affects performance. Component invocations that cross the network are much slower than component invocations in the same application domain or process.
· Licensing considerations may constrain the deployment of software components to specific servers.
Solution
Structure your servers and client computers into a set of physical tiers. A tier is composed of one or more computers that share one or more of the following characteristics:
· System resource consumption profile. The components hosted on the tier's servers may use a set of system resources, such as memory, sockets, and I/O channels, in a similar way. For instance, a solution may have a tier dedicated to Web servers and another to database servers. The Web servers consume a lot of network sockets and file descriptors, while the database servers consume a lot of file I/O bandwidth and disk space. Using multiple tiers enables you to optimize both the server configuration in the Web tier for Web access and the server configuration in the data tier for data access.
· Operational requirements. The servers in a tier often share common operational requirements, such as security, scalability, availability, reliability, and performance. For example, servers in a Web tier are often configured in a server farm for scalability and reliability, but the servers in a data tier are often configured as highly available clusters. Although tiered distribution affects all operational requirements, it has the most impact on the system-level operational requirements, such as system security, scalability, and availability.
· Design constraints. A tier may be dedicated to servers that share a common design constraint. For instance, an organization's security policy may dictate that only Web servers are allowed on the public side of the perimeter network (also known as DMZ, demilitarized zone, and screened subnet), and that conversely, all application logic and corporate databases must reside on the corporate side of the perimeter network.
The word "layer" is often used interchangeably with tier. However, this set of patterns makes a distinction between the two. Conceptually, a tier is the hardware equivalent of a software architecture layer (See Layered Application). Whereas layers logically structure your application's components, tiers physically structure your solution's servers. A useful heuristic for determining the number of tiers in a solution is to count the number of computers involved in realizing a use case. Do not count computers that are only loosely associated with a use case, such as display terminals, Web proxies, caches, and file servers. The rest of this pattern refers to this heuristic as the tiering heuristic.
Example
To provide a better understanding of just what a tier is, and the value provided by distributing your solution over multiple tiers, the following discussion works through an example of refactoring a monolithic single-tiered solution into a multi-tiered solution. The example is an order-processing application, and only considers one use case: Process Order. This use case is responsible for allowing a customer service representative to enter an order into the system.
· Single-Tiered Solution
Initially, the solution was designed for use by customer service agents and was deployed on a mainframe with the rest of the company's mission-critical applications. Figure 1 shows this distribution.
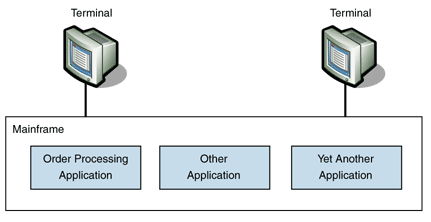
Figure 1: Single-tiered distribution
According to the tiering heuristic, Figure 1 is a single-tiered application. One computer does all the processing. The terminal does not perform any processing in support of the use case other than to accept input and provide output to the application's users.
Deployment and administration are very easy, because only one computer is involved.
As the number of users and the load each user puts on the system increase, more resources such as memory, processors, and disk space will be added to the system. Eventually, the expansion capabilities of the single computer will be exhausted and a second computer will be required. For mainframe-class computers, the cost associated with adding a new computer can be very high. This factor severely limits the options for scalability. At some point, adding a new user will cost you an additional mainframe and the associated infrastructure.
The terminal has no processing power of its own. All work is done on the mainframe, and the quality of the user experience is limited due to the limited user-interface functionality.
As long as all the users of the system are within the company's intranet, the security of the solution is quite high. Most companies add additional security precautions if the mainframe is exposed to the Internet.
Two-Tiered Solution
Several factors caused the company to switch to a two-tiered solution. First, the customer service representatives required more robust user interfaces. Second, the desire to take orders 24 hours per day affected the mainframe's batch-processing windows. Third, performance of the order-processing system was sometimes unacceptable when the mainframe was under a high load.
As a result of these factors, the order-processing system was removed from the mainframe and was rearchitected as a two-tiered fat-client solution. The fat-client architecture puts most of the business logic on the client tier, leaving the other tier to host the solution's database. Figure 2 shows this distribution.
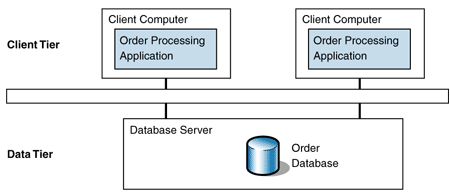
Figure 2: Two-tiered distribution
The Process Order use case now involves two computers and thus is a two-tiered solution according to the tiering heuristic. The user interacts with the order application on the client computer, and the order application then obtains the data required for the use case from the data tier.
Deployment and administration are now more complicated. The application must be distributed, installed, and configured on each client computer, and a separate installation for the server components (in this case, just the database) must be maintained.
Scalability significantly improves over the single-tiered solution. Each user has his or her own dedicated computer, so the only limit to scalability is how many concurrent users the database servers can handle. Compared to a mainframe, the database server is relatively low cost and can be dedicated to the order-processing application. This allows the database server to be optimized for the usage patterns of the order-processing application. If a single database server is ever unable to handle the load, an additional database server can be added.
Each user computer has it own processor and a robust graphical user interface. The order processing takes advantage of this by offering a much more interactive user interface that ultimately results in increased productivity from the customer service agents and lower error rates for the data entered.
Security is more complex in the two-tiered solution. Users typically log on to the client application. Additionally, the data tier often requires a separate authentication process. This requires the administration of two separate security systems and increases the number of potential security vulnerabilities.
Three-Tiered Solution
To better serve key customers, the company decided to expose its order processing application to some of its key customers through an extranet. To minimize deployment issues, the company decided to rearchitect the solution to allow access through a Web browser and rich-client interfaces. Figure 3 shows this distribution.
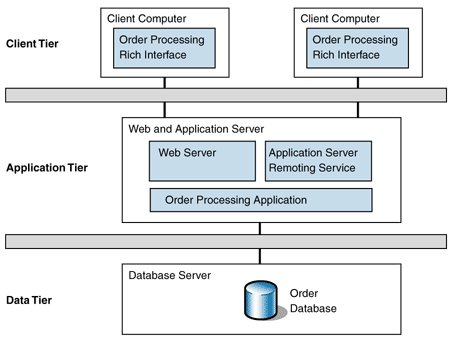
Figure 3: Three-tiered distribution
For more details about this distribution, see Three-Tiered Distribution. The following section discusses the effects of moving the example to a three-tiered distribution.
The Process Order use case now involves three computers and therefore is a three-tiered solution. The Web interface provides a basic interface to the order-processing system that allows customers to perform common operations fairly efficiently. For more complex tasks, customers must contact their customer support representative, who uses the rich interface to carry out the task. The business logic has been extracted out of the client tier and placed in its own application tier where many users can share it. This application tier invokes the services of the data tier for its data needs.
According to the tiering heuristic, it is the number of computers involved in processing a use case that determines the number of tiers, and not the number of computers per tier. For example, it is common for Web-based solutions to have multiple servers in the application tier arranged in a load balanced configuration. Because only one computer in the tier is involved with a given use-case instance, the tier adds only one computer to the tier count. Similarly, because the load balancer does not fundamentally advance the use-case processing, it does not count toward the tier count either.
Deployment and administration tasks are simpler than with two-tiered distribution, because most of the application logic is deployed on a centralized server. Therefore, clients usually do not have to be updated for application changes that do not require user interfaces changes. This is especially true for the browser-based user interfaces, which involve virtually no deployment effort. The rich interface that the customer support agents use involves somewhat more distribution effort, but the effort required is still significantly less than that involved in a fat-client installation.
The application tier is often the scalability bottleneck in Web applications. Not only does the application tier handle the Web server responsibilities, it also performs all of the business logic processing for the solution. The application tier is most often deployed in a server farm to achieve scalability and fault tolerance. A server farm is a set of identical servers with a load balancer that distributes work evenly across the server set. For more information, see Server Farm.
Configuring and tuning the application tier is more difficult due to the need to balance the differing server resource requirements of the Web server components and business processing components.
The database tier is virtually the same as described in a two-tiered distribution.
Computers on the client tier typically follow one of two strategies. For Web applications, the client tier uses the Web browser environment for interacting with the user. Minimal configuration and tuning of the client computers is required, other than adjusting network connectivity parameters and browser settings. As noted earlier, this significantly reduces the client's deployment and administrative costs. For rich applications, the client application uses the computer resources on the client computers to significantly enhance the user experience. Additionally, some tasks can be offloaded from the application tier at the expense of increasing the client computer's deployment and administration burden.
The security concerns of three-tiered distribution are similar to those of two-tiered distribution. However, the main security issue for this example is the fact that the solution is now exposed to users who are external to the company. As a result, a firewall configuration known as a perimeter network is usually placed between the application and data tiers. The application tier is on the public side of the perimeter network, because it also hosts the Web server, and most security professionals do not grant external users access to servers on the corporate side of the perimeter network.
Four-Tiered Solution
The company has decided to expose its order-processing application to all its customers over the Internet. Therefore, to increase security and scalability, the company has once again rearchitected its solution by separating the Web servers and applications servers into their own tiers. Figure 4 shows this distribution.
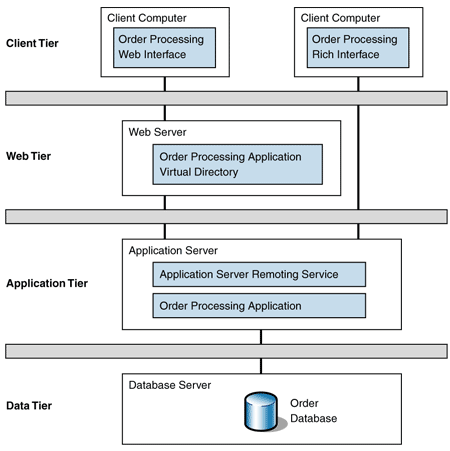
Figure 4: Four-tiered distribution
The Process Order use case now involves four computers and therefore is a four-tiered solution. The flow is the same as for three tiers, except that the Web servers have been separated into an additional tier, which adds one computer to the tier count.
Because four-tiered distribution is very similar to three-tiered distribution, much of the earlier discussion applies here. The primary areas where the two distributions differ are configuration, scalability, and security.
The servers in the Web tier consume a different set of resources than servers in the application tier. Therefore, separating them into separate tiers allows the two different server types to optimize their resource usage. The servers on the Web tier can now be optimized for Web server use, which typically involves lots of network sockets and I/O throughput; the application tier servers can be optimized for processing business transactions, which typically involves maximizing processor utilization, threading, and database connections.
The Web tier typically addresses scalability and fault-tolerance through a Server Farm as described earlier. The application tier addresses the same concerns through the use of Server Clustering. A server cluster is a set of servers configured for high-availability that appear to clients as one super server. For more information, see Server Clustering.
Separating the Web servers into a new tier enables the Web tier to be placed within the perimeter network and the application tier servers to be placed on the corporate side of the perimeter network. Now, if a fault allows unauthorized access to the Web server, sensitive information hosted on the application servers is not exposed.
Summary
The refactoring exercise in this pattern demonstrated several criteria for structuring your solution's tiers:
· Tiers were used to allow servers and client computers to be optimized for specific tasks, such as interacting with users, serving Web pages, and hosting databases.
· Tiers were used to separate servers that had different security profiles.
· Tiers were used to separate servers that had different scalability and fault-tolerance requirements.
· Tiers were used to reduce the administration and deployment overhead required of distributed applications.
You can address the vast majority of distribution scenarios by following one of the Tiered Distribution implementation patterns, such as Three-Tiered Distribution. If none of the implementation patterns address your requirements, see Deployment Plan for guidance on how to design your own deployment solution.
Resulting Context
This pattern results in a number of benefits and liabilities.
Benefits
The resulting context of the solution described in this pattern has the following benefits:
· Each tier can be optimized for specific resource usage profiles. For instance, servers in tiers that interact with a large number of client computers can be optimized for socket and file handle usage.
· Each tier can have a different security profile.
· Each tier can be designed for different operational characteristics. For instance, Web tiers usually achieve scalability and fault-tolerance through server farms, whereas database tiers usually achieve the same through server clusters.
· Each tier can be separately modified to respond to changes in load, requirements, hosting strategy, and so on. For example, you can scale out a Web tier to accept an increase in the number of users, independent of scaling up the database servers to accept an increase in the transactional throughput. This flexibility tends to reduce overall total cost of ownership, because servers can be added and removed as the business requirements and technical environment change.
· Tiers can be deployed to meet geographical, political, and legal requirements.
· Tiers ease some of the administrative and deployment burden associated with distributed solutions.
Liabilities
The benefits of the solution described in this pattern are offset by the following liabilities:
· Each tier involved in processing a client request degrades performance and adds application and system management overhead.
· Server clusters and server farms add cost and complexity to your infrastructure.
Related Patterns
For more information, see the following related patterns:
· Server Farm
· Application Server
Acknowledgments
[PnP02] patterns & practices, Microsoft Corporation. "Application Architecture for .NET: Designing Applications and Services." MSDN Library. Available at:http://msdn.microsoft.com/library/default.asp?url=/library/en-us/dnbda/html/distapp.asp.