Data Integration

Integration Patterns
Start |
Previous |
Next
Contents
Context
Problem
Forces
Solution
Example
Resulting Context
Testing Considerations
Security Considerations
Related Patterns
Acknowledgments
Context
Enterprise information systems are comprised
of a variety of data storage systems, which vary in complexity
and in the ways they access internal data. An example of a
simple data storage system is a flat file. An example of a far
more complex data storage system is a Database Management System
(DBMS) server farm.
Problem
How do you integrate information systems that were not
designed to work together?
Forces
- Most enterprises contain multiple systems that were
never designed to work together. The business units that
fund these information systems are primarily concerned with
functional requirements rather than technical architectures.
Because information systems vary greatly in terms of
technical architecture, enterprises often have a mix of
systems, and these systems have incompatible architectures.
- Many applications are organized into three logical
layers: presentation, business logic, and data.
- When you integrate multiple systems, you usually want to
be as noninvasive as possible. Any change to an existing
production system is a risk, so it is wise to try to fulfill
the needs of other systems and users while minimizing
disturbance to the existing systems.
- Likewise, you usually want to isolate applications'
internal data structures. Isolation means that changes to
one application's internal structures or business logic do
not affect other applications. Without isolated data
structures, a small change inside an application could cause
a ripple effect and require changes in many dependent
applications.
- Reading data from a system usually requires little or no
business logic or validation. In these cases, it can be more
efficient to access raw data that a business layer has not
modified.
- Many preexisting applications couple business and
presentation logic so that the business logic is not
accessible externally. In other cases, the business logic
may be implemented in a specific programming language
without support for remote access. Both scenarios limit the
potential to connect to an application's business logic
layer.
- When making updates to another application's data, you
should generally take advantage of the application's
business logic that performs validations and data integrity
checks. You can use
Functional Integration to
integrate systems at the logical business layer.
- Direct access to an application's data store may violate
security policies that are frequently implemented in an
application's business logic layer.
- The availability of commercial tools can influence the
integration strategy between applications. Commercial tools
usually carry a lower risk and expense when compared to a
custom solution.
Solution
Integrate applications at the logical data layer by allowing
the data in one application (the source) to be accessed by other
applications (the target), as shown in Figure 1.
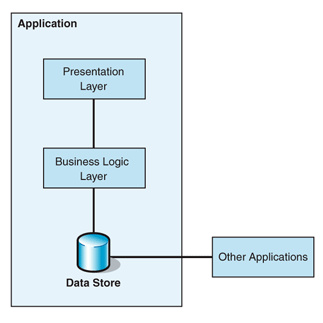
Figure 1. Integrating applications at the
logical data layer
To connect applications at the logical data layer, use one or
more of the following patterns:
- Shared Database. All applications that you are
integrating read data directly from the same database.
- Maintain Data Copies. Maintain copies of the
application's database so that other applications can read
the data (and potentially update it).
- File Transfer. Make the data available by
transporting a file that is an extract from the
application's database so that other applications can load
the data from the files.
When you are implementing Data Integration, you
usually have to consider the following design tradeoffs:
- Latency tolerance. Some forms of data integration
imply a delay between updates to the data that is used by
multiple applications. For example, in the
Data Replication pattern [Teale03], the data is
extracted from the source system, and it is transported over
a network. The data might then be modified, and then it is
inserted in a target database. This delay means that one
system may have access to data that is more up to date than
another system. This latency in propagating data can play an
important role in integration.
- Push versus pull. When accessing a data source's
database, a system can either pull the data from the
database or let the database itself push the data when a
change occurs. Pull approaches are generally less intrusive,
while push approaches minimize latency.
- Granularity. Getting a larger chunk of
information at one time is generally more efficient than
propagating each small change by itself. This requires an
understanding of the cohesion between multiple data
entities. If one entity changes, are other entities also
likely to be affected?
- Master/subordinate relationships. If updates are
made only to one application's data, propagating these
changes is relatively simple. However, if multiple
applications are allowed to update the information, you can
run into difficult synchronization issues. For a more
detailed description of synchronization issues, see the
Master-Master Replication pattern [Teale03].
- Synchronization logic versus latency. For
geographically dispersed applications, sharing a single
database may cause excessive network latency. To overcome
this problem, you can use distributed databases that contain
copies of the same data. However, distributed databases add
the additional complexity of synchronization and replication
logic.
Example
There are many real-life examples of Data Integration.
For example, an order entry application may store a copy of
product codes that reside in the Enterprise Resource Planning
(ERP) system. If product codes do not change very frequently,
the data from the source (the ERP system) may be synchronized
daily or weekly with the data on the target (the order-entry
application).
Resulting Context
After you decide to use Data Integration, you must
then choose a particular kind of data integration that is
appropriate for your situation. Your choices are summarized by
the following patterns:
- Shared Database
- Maintain Data Copies
- File Transfer
Shared Database
The Shared Database approach is shown in Figure 2.
Shared Database aims to eliminate latency by allowing
multiple applications to access a single physical data store
directly. This approach is more intrusive because you usually
have to modify some applications to use a common schema.
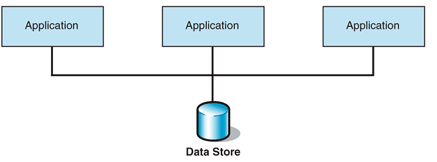
Figure 2. Shared Database
Reading data directly from a database is generally harmless,
but writing data directly into an application's database risks
corrupting the application's internal state. Although
transactional integrity mechanisms protect the database from
corruption through multiple concurrent updates, they cannot
protect the database from the insertion of bad data. In most
cases, only a subset of data-related constraints is implemented
in the database itself. Other constraints are likely to be
contained in the business logic. This distribution of data
constraints allows other applications to leave the database in a
state that the application logic considers to be invalid. For a
more detailed description, see Martin Fowler's Shared
Database pattern in Hohpe and Woolf's Enterprise
Integration Patterns [Hohpe04].
Maintain Data Copies
Instead of sharing a single instance of a database between
applications, you can make multiple copies of the database so
that each application has its own dedicated store. To keep these
copies synchronized, you copy data from one data store to the
other.
This approach is common with packaged applications because it
is not intrusive. However, it does imply that at any time, the
different data stores are slightly out of synchronization due to
the latency that is inherent in propagating the changes from one
data store to the next. Figure 3 shows the Data Replication
pattern, which is a derivative of Maintain Data Copies.
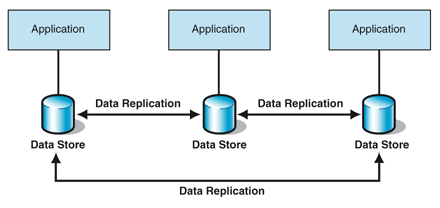
Figure 3. Data Replication
The mechanisms involved in maintaining these copies are
complex. Data Patterns discusses these mechanisms in a
cluster of 12 data movement patterns [Teale03] that use
Maintain Data Copies as a root pattern. The other patterns
in the guide include the following:
- Move Copy of Data
- Data Replication
- Master-Master Replication
- Master-Slave Replication
- Master-Master Row-Level Synchronization
- Master-Slave Snapshot Replication
- Capture Transaction Details
- Master-Slave Transactional Incremental Replication
- Implementing Master-Master Row Level Synchronization
Using SQL Server
- Implementing Master-Slave Snapshot Replication Using
SQL Server
- Master-Slave Cascading Replication
For more details about these patterns, see Data Patterns
on MSDN (http://msdn.microsoft.com/architecture/patterns/default.aspx?pull=/library/en-us/dnpatterns/html/Dp.asp).
File Transfer
In the File Transfer pattern, one application produces
a file and transfers it so that other applications can consume
it. Because files are a universal unit of storage for all
enterprise operating systems, this method is often simple to
implement. The disadvantage of this method is that two
applications can lose synchronization with each other because
each one is changing the file independently. For more
information, see Martin Fowler's File Transfer pattern
[Hohpe04].
Choosing Between Alternatives
There are many factors to consider when you choose the kind
of data integration that is best for your particular
requirements. Some of those factors include:
- Tolerance for data that is not current (stale data)
- Performance
- Complexity
- Platform infrastructure and tool support
After you pull data from a transactional system, the data is
effectively stale. When you attempt to modify the data, you
encounter potential contention and conflict resolution logic. If
your conflict resolution logic is simple, and if you can
accommodate relatively long time intervals with stale data,
File Transfer may be the best way to integrate data.
If your conflict resolution logic is more complex, and if you
have less tolerance for stale data, consider Shared Database
or Maintain Data Copies. Before deciding on one or the
other, consider your performance needs.
If your applications and databases are located in the same
data center, then Shared Database enables you to use
transaction managers to enforce data consistency. Using
transaction managers to enforce data consistency limits stale
data. However, if you have too many applications accessing the
same data, the database may become a performance bottleneck for
your system.
Maintaining multiple copies of the same data reduces the
performance bottleneck of a single database, but it creates
stale data between synchronizations. Also, if your application
is geographically distributed, sharing one single database
creates excessive network latency and affects performance.
Maintain Data Copies also presents its own operations
challenges. However, you can reduce the effort associated with
maintaining multiple copies by using the synchronization and
replication capabilities that are built into many DBMSs.
As you can see, each form of data integration has advantages
and disadvantages. Choosing the right kind of data integration
depends on the factors that are most important to your
organization and on achieving the right balance among the
tradeoffs.
Benefits
- Regardless of the type of data integration you choose,
the benefits are as follows:
- Nonintrusive. Most databases support
transactional multiuser access, ensuring that one user's
transaction does not affect another user's transaction. This
is accomplished by using the Isolation property of the
Atomicity, Consistency, Isolation, and Durability (ACID)
properties set. In addition, many applications permit you to
produce and consume files for the purpose of data exchange.
This makes Data Integration a natural choice for
packaged applications that are difficult to modify.
- High bandwidth. Direct database connections are
designed to handle large volumes of data. Likewise, reading
files is a very efficient operation. High bandwidth can be
very useful if the integration needs to access multiple
entities at the same time. For example, high bandwidth is
useful when you want to create summary reports or to
replicate information to a data warehouse.
- Access to raw data. In most cases, data that is
presented to an end user is transformed for the specific
purpose of user display. For example, code values may be
translated into display names for ease of use. In many
integration scenarios, access to the internal code values is
more useful because the codes tend to more stable than the
display values, especially in situations where the software
is localized. Also, the data store usually contains internal
keys that uniquely identify entities. These keys are
critical for robust integration, but they often are not
accessible from the business or user interface layers of an
application.
- Metadata. Metadata is data that describes data.
If the solution that you use for data integration connects
to a commercial database, metadata is usually available
through the same access mechanisms that are used to access
application data. The metadata describes the names of data
elements, their type, and the relationships between
entities. Access to this information can greatly simplify
the transformation from one application's data format to
another.
- Good tool support. Most business applications
need access to databases. As a result, many development and
debugging tools are available to aid in connecting to a
remote database. Almost every integration vendor provides a
database adapter component that simplifies the conversion of
data into messages. Also, Extract, Transform, and Load (ETL)
tools allow the manipulation of larger sets of data and
simplify the replication from one schema to another. If
straight data replication is required, many database vendors
integrate replication tools as part of their software
platform.
Liabilities
Regardless of the type of data integration you choose, the
liabilities are as follows:
- Unpublished schemas. Most packaged applications
consider the database schema to be unpublished. This means
that the software vendor reserves the right to make changes
to the schema at will. A solution based on Data
Integration is likely to be affected by these changes,
making the integration solution unreliable. Also, many
software vendors do not document their database schemas for
packaged applications, which can make working with a large
physical schema difficult.
- Bypassed business logic. Because data integration
accesses the application data store directly, it bypasses
most of the business logic and validation rules incorporated
into the application logic. This means that direct updates
to an application's database can corrupt the application's
integrity and cause the application to malfunction. Even
though databases enforce simple constraints such as
uniqueness or foreign key relationships, it is usually very
inefficient to implement all application-related rules and
constraints inside the database. Therefore, the database may
consider updates as valid even though they violate business
rules that are encoded in the application logic. Use
Functional Integration instead of Data Integration
if you need the target application to enforce complex
business rules.
- No encapsulation. Accessing an application's data
directly provides the advantage of immediate access to raw
data. However, the disadvantage is that there is little or
no encapsulation of the application's functionality. The
data that is extracted is represented in the format of an
application-internal physical database schema. This data
very likely has to be transformed before other applications
can use it. These transformations can become very complex
because they often have to reconcile structural or semantic
differences between applications. In extreme scenarios, the
data store may contain information in a format that cannot
be used by other systems. For example, the data store might
contain byte streams representing serialized business
objects that cannot be used by other systems.
- Simplistic semantics. As the name suggests,
Data Integration enables the integration of data only.
For example, it enables the integration of data contained in
entities such as "Customer XYZ's Address." It is not
well-suited for richer command or event semantics such as
"Customer XYZ Moved" or "Place Order." Instead, use
Functional Integration for these types of integration.
- Different storage paradigms. Most data stores use
a representation that is different from the underlying
programming model of the application layer. For example,
both relational databases and flat-file formats usually
represent entities and their relationships in a very
different way from an object-oriented application. The
difference in representation requires a translation between
the two paradigms.
- Semantic dissonance. Semantic dissonance is a
common problem in integration. Even though you can easily
resolve syntactic differences between systems, resolving
semantic differences can be much more difficult. For
example, although it is easy to convert a number into a
string to resolve a syntactic difference, it is more
difficult to resolve semantic differences between two
systems that have slightly different meanings for the Time,
Customer, and Region entities. Even though two databases
might contain a Customer entity, the semantic context of
both entities might be dramatically different.
Testing Considerations
Testing data integration solutions can be difficult for a
number of reasons, including the following:
- The direct access to the data source and destination
does not allow isolation of a specific function. For
example, using a test stub or mock object does not allow
isolation of a specific function. If the data exchange uses
a file to transfer data, you can use test files to test the
data insertion.
- Inserting data directly into the target database
bypasses all or most business logic. Therefore, testing the
insert itself may not be very meaningful because it is
likely to succeed. Even if the data is inserted successfully
into the database, the data may violate another
application's business logic. As a result, the complete
application may have to be regression tested after you
insert data directly into the application data store.
- Because Data Integration puts few constraints on
the data to be inserted into an application's data store, a
large data set may be required to provide appropriate
coverage of all test cases.
Security Considerations
Data Integration presents potential security issues
that are worth considering:
- Coarse-grained security. Because Data
Integration bypasses the application logic, it also
bypasses any security rules that are enforced by the
application logic. Many databases manage access privileges
at the table level. At the table level, a user either has
access to the Customer table or the user does not have
access. Most applications enforce security at an object
level. At the object level, a specific user has access only
to those customer records that are associated with the user.
- Privacy policies may not be enforced. Many
corporate databases are subject to privacy policies that are
based on corporate or legal guidelines. Directly accessing
these data stores may be in violation of these policies
because it is difficult to control the ways the retrieved
data may be used. In comparison, Functional Integration
can offer restricted access to sensitive data to only allow
queries that do not expose individual data. For example, a
functional interface may allow the user to query the average
compensation in a specific region but not individual
compensation.
- Data may be encrypted. Data inside the database
may be encrypted so that it is not accessible for data
integration unless the integration solution obtains the key
to decrypt the data. Providing the key to the data
integration solution could present a security risk unless
the key is properly protected.
Related Patterns
For more information, see the following related patterns:
-
Functional Integration. Data Integration is used
to extract data from or insert data into an existing
application. If direct access to the data source must be
avoided, use Functional Integration instead.
Functional Integration interfaces with an application's
business logic.
- Data Consistency Integration [Ruh01]. In cases
where inserting data into an application is tied to specific
business rules and validations, straight data integration
might not be the best solution because the business logic
has to be re-created for the data insert operation. In these
cases, consider using Functional Integration to
achieve data consistency.
Acknowledgments
[Britton01] Britton, Chris. IT Architectures and
Middleware–Strategies for Building Large, Integrated
Systems. Addison-Wesley, 2001.
[Hohpe04] Hohpe, Gregor, and Bobby Woolf. Enterprise
Integration Patterns: Designing, Building, and Deploying
Messaging Solutions. Addison-Wesley, 2004.
[Ruh01] Ruh, William. Enterprise Application Integration.
A Wiley Tech Brief. Wiley, 2001.
[Teale03] Teale, Phil, et al. "Data Patterns.".NET
Architecture Center. June 2003. Available at:
http://msdn.microsoft.com/architecture/patterns/default.aspx.
Start |
Previous |
Next