Entity Aggregation
ContentsContextEnterprise-level data is distributed across multiple repositories in an inconsistent fashion. Existing applications need to have a single consistent representation of key entities which are logical groups of related data elements such as Customer, Product, Order, or Account. Moving data between these repositories may not be a viable option. ProblemHow can enterprise data that is redundantly distributed across multiple repositories be effectively maintained by applications? ForcesThe following forces have to be considered in this context:
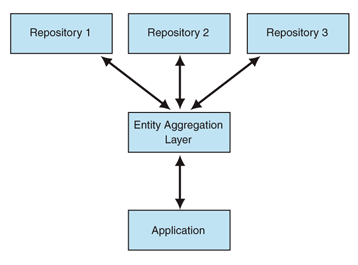
SolutionIntroduce an Entity Aggregation layer that provides a logical representation of the entities at an enterprise level with physical connections that support the access and that update to their respective instances in back-end repositories. This representation is analogous to the Portal Integration pattern, which presents to the end user a unified view of information that is retrieved from multiple applications. Similar to the portal layer that provides this view for the application front ends, the Entity Aggregation layer provides a similar view across the data in the back-end repositories as shown in Figure 1.
Figure 1. Entity Aggregation Establishing Entity Aggregation involves a two-step process:
The following example explains this process in more detail.
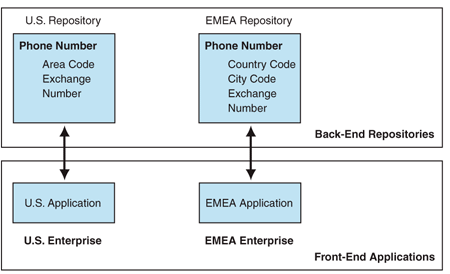
Figure 2. Environment without Entity Aggregation Figure 2 shows two applications that access their respective back-end repositories for information about the Phone Number entity within two different enterprises: U.S. Enterprise and the Europe, Middle East, and Asia (EMEA) Enterprise. Both applications maintain the information about the phone number within their respective repositories. Each application follows the respective domestic convention for representing phone numbers in its back-end repository. The U.S. representation of the entity includes the area codes, the exchanges, and the numbers. The EMEA representation, on the other hand, represents the same information using the country code, the city code, the exchange, and the number. As part of a merger and acquisition exercise, these enterprises merge to form a new logical enterprise. Both applications have to access the information in both repositories. Therefore, the phone number now has to be represented at an enterprise-wide level that includes both the U.S. and the EMEA business units.
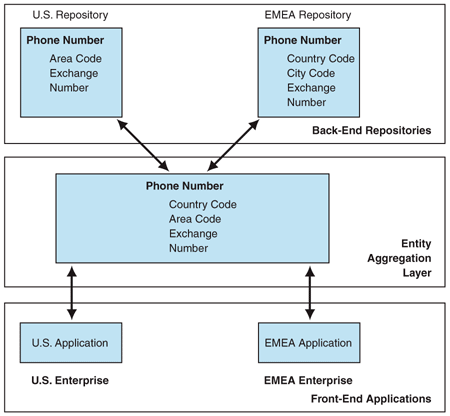
Figure 3. Environment with Entity Aggregation Figure 3 shows the manner in which Entity Aggregation can facilitate the seamless representation of the Phone Number entity across both repositories. The first step in establishing this layer involves defining the enterprise-wide representation of the Phone Number entity. The Phone Number entity within the Entity Aggregation layer includes attributes that are unique to each enterprise. The Phone Number entity also includes attributes that are common across both enterprises. Thus, Country Code is included because it is an attribute unique to the EMEA enterprise. Similarly, because Exchange and Number are common attributes across both repository instances, they are also included. Even though Area Code and City Code are unique to each enterprise, their basic representation and purpose is identical. Therefore, the Entity Aggregation layer representation chooses to include the Area Code while using this field to store the City Code information from the EMEA repository. The next step involves building the physical connections between the Entity Aggregation layer and the back-end U.S. and EMEA repositories. The technology driving these connections depends on the repository being accessed. ApproachThere are two architectural approaches to implementing Entity Aggregation:
Depending on the architectural characteristics of the entity instances to be integrated, a combination of these approaches may be required. Straight-Through ProcessingA straight-through processing approach fetches information from the respective back-end repositories in real time and correlates the information into a single unified view. This implies that the Entity Aggregation layer has real-time connectivity to the repositories and should be able to associate the disparate instances of the entity. ReplicationThe replication of entities for use by the Entity Aggregation layer is required when the following conditions are true:
This approach requires a separate physical repository within the Entity Aggregation layer that stores data conforming to the enterprise-wide representation of the entity. The data in each back-end repository is replicated into the Entity Aggregation repository. This replication requires the implementation of supporting processes to enforce the business rules that validate the data being replicated. Replication should be performed both ways between the back-end repositories and the Entity Aggregation repositories. In many respects, this approach offers capabilities very similar to those supported by a data warehouse. Data warehouses originally were built with the intent of summarizing transactional data that could be used for business intelligence and trends analysis. In many large enterprises today, data warehouses have transformed into yet another repository within the enterprise. They do not always serve as the enterprise-wide unified representation of the data. However, such data warehouses have a good baseline definition for enterprise-level entities, and the enterprise-wide representation of an entity can be built on top of this definition. Design ConsiderationsEffective design of an Entity Aggregation layer requires several issues to be given due consideration. These issues may be broadly classified as follows:
Each of these issues is outlined in the following sections. Entity RepresentationThere are several approaches that could be adopted to defining the enterprise-wide representation of the entity. Entity representations may have to be custom developed to address the specific needs of the enterprise as whole. This may be the only viable option under the following circumstances:
However, custom representations are not always a financially viable option because they require a regeneration of the existing entities and their relationships. Instead, a representation that is foreign to all the applications within the enterprise may be a viable approach as long as it still conforms to the core business processes. You could also use current representations that are specific to certain industries for this purpose. In other words, embracing an external representation does not necessarily entail the additional expense of procuring an application. In other cases, you could choose the representation supported by one of the existing applications within the enterprise. ERP and CRM applications that support and drive the business processes for the enterprise are prime candidates for this approach. While Entity Aggregation is all about having a single view of entities across the enterprise, entity representations within this layer might have to be adjusted to represent the nuances of individual business units. This is especially true for large international conglomerates that have been forced into being a logical enterprise through acquisitions and mergers of other enterprises that operate as autonomous business units. Reaching a consensus on the representation within any one of these units can be a challenge. Therefore, reaching a similar consensus across all of these units can be an ambitious goal, if not an impossible one. In these cases, multiple representations (one for each operating unit) might be a more realistic and practical approach. Schema ReconciliationEven if the enterprise reaches consensus on the entity representation, the representation within each instance of the entity may still vary across different repositories. Different repositories can hold different schemas for the same entity. The Entity Aggregation layer must harmonize the subtle differences between these schemas in the following ways:
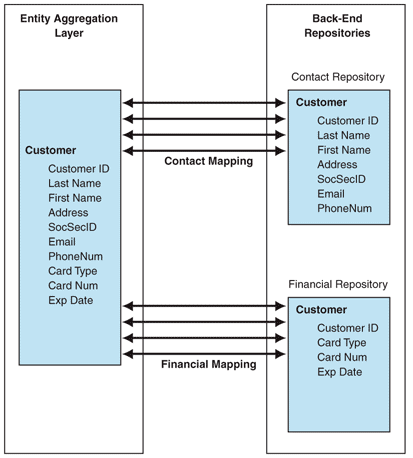
Note Sometimes, the term canonical schema is used instead of unified view. This pattern uses the latter term, because canonical schema implies that all the representations share the same schema, which is not always necessary. Figure 4 shows an example of customer information that is represented in more than one repository. Although the contact repository defines the contact information for a customer, the financial repository defines the credit card details for the customer. The Entity Aggregation layer defines a unified schema that contains all the attributes required for representing the customer entity. The Entity Aggregation layer also defines the mapping between the unified schema and those schemas held by the individual repositories.
Figure 4. Schema reconciliation ReferencesEntity reference is the information required to uniquely identify an entity. Repositories that store instances of a given entity tend to maintain their own unique identifiers for their respective instances to ensure they have full control over internal data consistency. The Entity Aggregation layer should account for this and should be able to map references that point to a single instance. Apart from references that are held by other repositories, the Entity Aggregation layer might create its own reference for an entity instance. The idea here is that the Entity Aggregation layer maintains its own reference to an entity instance and maps this reference to the individual repository's reference. This reduces the coupling between the Entity Aggregation layer and individual repositories because new repositories can be introduced without affecting the Entity Aggregation layer's unified view. Master ReferenceEntity Aggregation layer uniquely identifies an entity instance by using a reference known as a master reference. A master reference could be:
Inquiry vs. UpdateThe technological solutions available today are more robust for inquiring than they are for updating data in the back-end repositories. Updating has the inherent challenges of maintaining the synchrony of data across repositories. Note In the context of this pattern, deleting an entity is considered to be a form of update. An update request usually contains two elements: a reference that uniquely identifies the instance and an update payload that contains information about the updated attributes and their respective values. The Entity Aggregation layer uses entity references across all the repositories to perform the inquiries and updates. Although the Entity Aggregation layer maintains the entity reference, the references that are unique to each repository have to be determined before the update is made to the back-end repositories. For more information, see "References." CompensationThe process of performing a compensating action can be manual or automatic. Business process owners have a strong influence on the manner in which compensating actions should be implemented. If one of the systems fails to handle the update request, the Entity Aggregation layer should be able to handle this business exception by using one of the following approaches:
OwnershipAlthough the Entity Aggregation layer represents the unified view of an entity, it is certainly possible to store different fragments of an entity in different systems. Therefore, the system of record is not the same for all fragments. For example, employee information could be distributed across the payroll and benefits repositories. It is also possible that some information may be owned by multiple systems. For example, attributes such as LastName and FirstName are probably represented in more than one system. In this case, the Entity Aggregation layer should designate a system as an authoritative source for attributes that are represented in more than one system. This has several implications for the behavior that occurs during inquiries and updates. Attributes will always be fetched from the authoritative source. If the same attribute is represented by another system, those values will be ignored by the Entity Aggregation layer. Updates, on the other hand, have different semantics. When the Entity Aggregation layer receives an update request for an entity, the updates should be propagated to all the constituent systems of record. Change ManagementProcesses have to be put in place to coordinate changes across all the repositories and the Entity Aggregation layer. In addition to ensuring active participation from the different business process owners and information technology (IT) representatives for each repository, a key step in this process is to ensure that the integrity of the enterprise-wide representation of the entity is not compromised. Three types of changes to the underlying repositories can directly and significantly affect the Entity Aggregation layer:
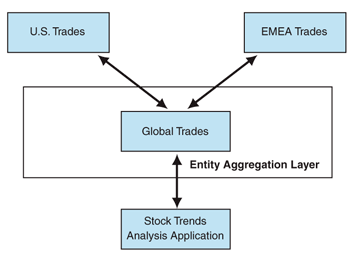
ExampleFigure 5 shows a scenario where the Stock Trade entity is partitioned across systems based on geographical constraints. Applications that analyze the trends in a given industry require a complete view of the trades across geographical boundaries and systems. The Entity Aggregation layer consolidates the view across geographical boundaries so that the partitioning of data across the repositories is transparent to the applications that perform trends analysis.
Figure 5. Stock trades scenario Resulting ContextEntity Aggregation has the following benefits and liabilities: Benefits
Liabilities
Testing ConsiderationsThe following testing considerations apply when adding an Entity Aggregation layer:
Security ConsiderationsThe Entity Aggregation layer is effective at providing access to information that is pertinent to business entities at an enterprise level. However, applications might be able to obtain access to repositories that may not have been available prior to the introduction of the Entity Aggregation layer. Even though applications might still operate on the same data elements, they might access new repositories through the Entity Aggregation layer. Access privileges for various roles within these applications have to be managed at the Entity Aggregation layer. Operational ConsiderationsThere are two separate operational aspects to the Entity Aggregation layer:
Known UsesEnterprise Information Integration is another industry term that is used to identify the enterprise-wide representation of a logical data model that houses the key business entities that have bidirectional physical connections to the back-end repositories where data is stored. Some companies provide a logical metadata modeling approach that allows enterprises to reuse models and data for real-time aggregation and caching with update synchronization. These companies initially provided query-only capability, but they are slowly beginning to support bidirectional transfer of data between the Entity Aggregation layer and the back-end repositories. Related PatternsGiven that the Entity Aggregation layer provides a view of data that is distributed across repositories, Data Integration is closely related to this pattern. |