|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Version 1.0.0
GotDotNet community for collaboration on this pattern
Complete List of patterns & practices
Context
You are about to design a replication between a source and a target, as described in Master-Master Replication. Your requirements are:
Note: This pattern uses relational database terms to discuss the solution, but the solution will work in other contexts. The pattern also assumes the existence of relational database management system (RDBMS) services, such as change logging.
Problem
How do you design a replication to transmit data from the source to the target and vice versa, when the same replication set is updateable at either end of the replication and you want to resolve conflicts at the row level?
Forces
All of the forces that were described in the Master-Master Replication pattern apply in this context, and there is one additional one. The relevant forces are repeated here for convenience.
Any of the following compelling forces would justify using the solution described in this pattern:
If you cannot afford the risk of conflicts, you may choose to use the Pessimistic Concurrency Control pattern. (Both OptimisticConcurrency Control and Pessimistic Concurrency Control are patterns described in [Fowler03].)
The following enabling forces facilitate the adoption of the solution, and their absence may hinder such a move:
Solution
Create a pair of related replication links between the source and target as described in the Master-Master Replication pattern. Additionally, create a synchronization controller to manage the synchronization and connect the links. This solution describes the function of one of these replication links. The other replication link behaves the same way, but in the opposite direction. To synchronize more than two copies of the replication set, create the appropriate replication link pair for each additional copy.
Hint: When designing the replication link, it is important to know what types of conflicts can occur and how to handle them so that the integrity of replicated data remains intact. The design of conflict detection and conflict resolution is described in the Master-Master Replication pattern.
Figure 1 shows the use of the replication building block and its elements to design the solution for master-master synchronization, and the added services to manage the relationship between the pair of links.
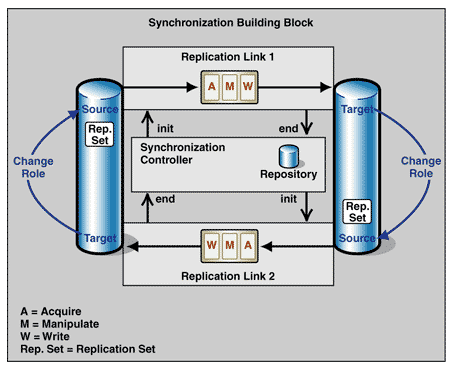
Figure 1: Master-Master Synchronization using two related replication links
Controller
The synchronization building block is an extension of the replication building block and consists of two replication links and a synchronization controller. The controller manages the synchronization and relates the replication link pair.
The controller uses a small repository to keep track of the transactions. This repository contains information about the replication links and the transmissions on each of them. Figure 2 shows a data model for this repository.
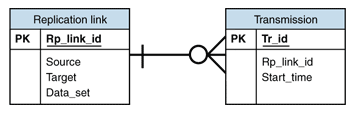
Figure 2: Database design for handling synchronization data
At the start of every transmission, the controller reads the start time of the last synchronization for this replication link from the repository. It then invokes the Acquire service to get the replication set from the source. The controller waits until the Write service notifies it that it has written the replication set to the target, and then the controller invokes the Acquire service of the second replication link to get the target's replication set. This replication set now serves as the source for the second link, and the source for the first link now serves as the target for the second link. When the transmission is complete, the Write service of the second link notifies the controller. Finally, the controller writes the start time for this synchronization into the repository, which shows that the synchronization is complete.
Source/Target
To use this pattern, you must ensure that the following is true on the source and target:
Hint: Marking updates requires that you add columns to the existing tables. If you cannot add these columns, then you need to create a shadow table for every table in the replication set. These have the same primary keys as the main tables and they store the date/timestamps, and delete flags. Changes to these tables need to be synchronized too.
When the application makes changes to the rows of the source, it also writes information for the replication link to use, as Table 1shows.
Table 1: Additional Application Actions to Identify the Replication Set
| Operation | Action |
|---|---|
| INSERT | The new row is marked for transmission by the next transmission. |
| UPDATE | The new row is marked for transmission by the next transmission. |
| DELETE | The updated row is marked for transmission by the next transmission. |
If you are using an RDBMS, you can use one of the following means to mark and log the rows without changing the application:
Acquire
In this pattern, the Acquire service is invoked by the controller module and is passed its context. It reads the replication set to get the rows that have been changed or marked as deleted since the last transmission.
Manipulate
There are no special considerations for the Manipulate service in a synchronization environment other than all manipulations of the data must be reversible. This is because the related replication link must perform the complementary manipulations of this service. For example, if you concatenate a bank code number and an account number in the first transmission, then you must be able to split this string on the reverse transmission.
Write
Since the solution uses optimistic concurrency control, the Write service must check for conflicts before writing to the target. Methods for conflict detection and resolution are presented in the Master-Master Replication pattern.
If a conflict has been detected, an appropriate conflict resolution method must be called, which either returns the winner or a new row to be written instead of the original one. If the conflict resolution method accepts changes from the source, or if it returns a modified row, this row is to be written to the target. However, if the conflict resolution rejects the row from the source, it must be discarded and must not be written to the target.
Hint: Use of DELETE flags leads to a need for cleanup, which means that at some point you need to physically delete these rows from all the copies that they exist in. To do this, each copy needs to know the synchronization times for all directly related replications so that it can use these times to know which rows can safely be deleted. Rows whose timestamp is older than any of the related synchronization times can be deleted.
Example
This example outlines a common implementation of the Master-Master Row-Level Synchronization pattern. The replication unit is a row. The rows in the replication set are marked with a timestamp and a delete flag. Hence, every table has two additional columns. The applications must not read any rows that are marked as deleted, and it should never read the additional columns (that is, do not use statements such as SELECT * FROM).
Figure 3 shows the algorithm for detecting and resolving conflicts when timestamps and delete flags are used. In this case, the most recent timestamp wins. If the row in the transmission has the most recent timestamp, it is written to the target. If it doesn't, the target row is left untouched and the transmission row is discarded. Overall integrity will be restored when the related replication link runs.
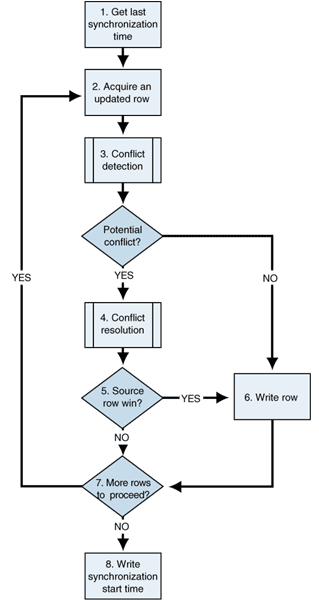
Figure 3: Synchronization algorithm for most recent timestamp wins
The following list provides more information about each step in the algorithm shown in Figure 3.
Algorithm using timestamps for conflict detection
1.Get the last synchronization time from the Controller.
2.Acquire a row from the replication set.
3.Conflict detection: Check the corresponding target row to see if it has been changed since the last synchronization by comparing the target timestamp with the synchronization timestamp.
4.Potential conflict?
No: If the timestamp of the target row is older than the synchronization timestamp, the row has not changed and you can write the UPDATE; skip to step 7.
If there is no corresponding target row, then assume this is an INSERT and skip to step 7.
Yes: If the target row has changed, use conflict resolution.
5.Conflict resolution: Apply the conflict resolution rules. This example uses the "latest timestamp" rule, so compare the target row timestamp and the transmission row timestamp.
6.Source row win?
Yes: If the timestamp on the transmission row from the source is more recent, proceed to step 7.
No: Discard the transmission row and skip to step 8.
7.Write the transmission row to the target.
8.More changed rows?
Yes: If there are more changed rows, repeat the sequence beginning at step 2.
No: If there are no more changed rows, proceed to step 9.
9.Write the start time of the synchronization into the Controller metadata.
An implementation of a synchronization with row-level conflict resolution based on the services of Microsoft SQL Server is presented in Implementing Master-Master Row-Level Synchronization Using SQL Server.
Resulting Context
This pattern inherits the benefits and liabilities of the Data Replication and the Master-Master Replication patterns, which are not repeated here. It also has one additional liability.
Additional Liability
Cleanup after synchronization of DELETE operations. During synchronization you must not physically delete the rows until the information about the deletion is transmitted to targets. Eventually, after all transmissions are complete, you should physically delete the rows.
Operational Considerations
When using Master-Master Row-Level Synchronization, you must ensure that the transmissions do not interfere with normal operations. This can be achieved by one of these alternatives:
Related Patterns
For more information, see the following related patterns:
Patterns That May Have Led You Here
Patterns That You Can Use Next
Other Patterns of Interest
Acknowledgments
[Fowler03] Fowler, Martin. Patterns of Enterprise Application Architecture. Addison-Wesley, 2003